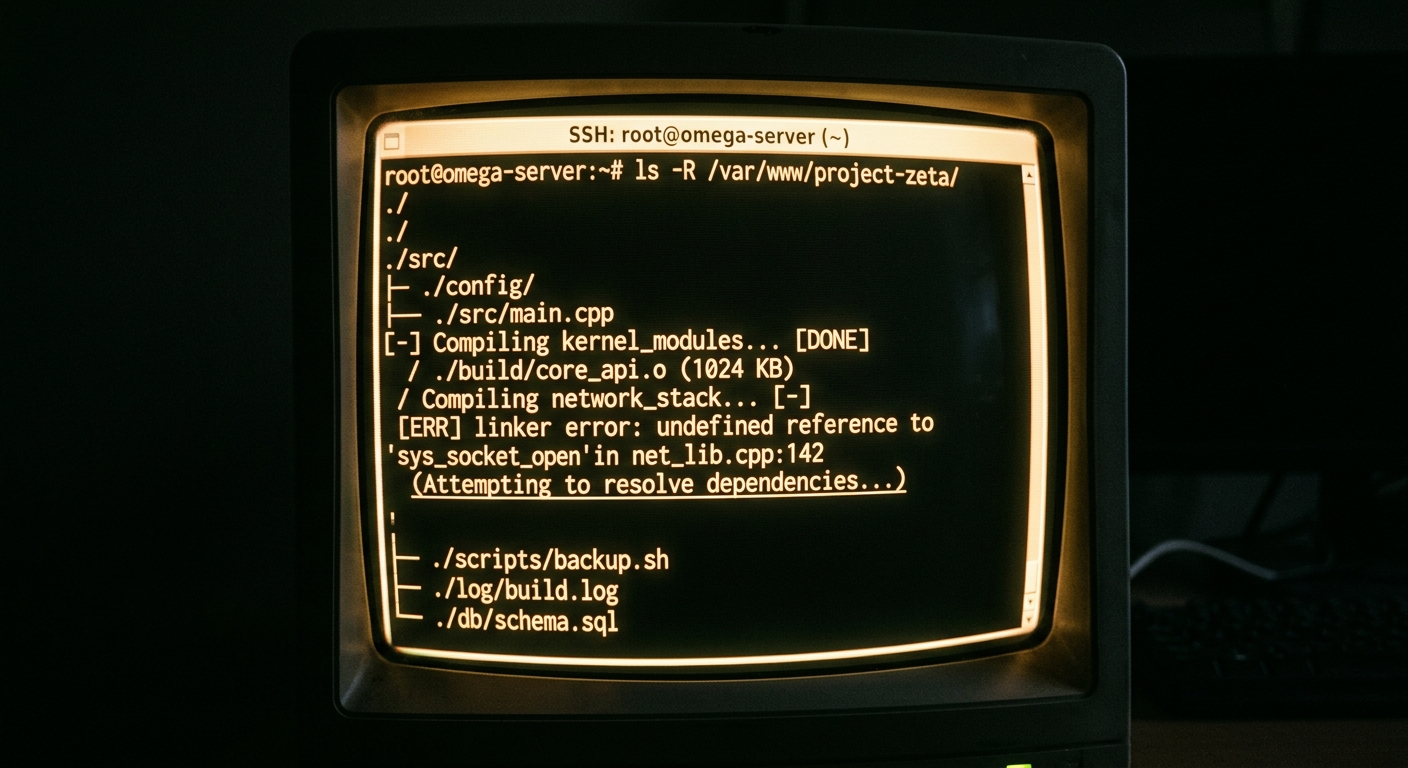
A three-week-old index is worse than no index at all. Last Tuesday, I shipped a regression that cost us four hours of uptime. The cause was simple. I used a tool that told me a specific helper function was unused across our 1.2 million line monorepo. I deleted it. I ran the tests. They passed because the test suite only covers the happy path for that legacy module. I pushed.
It turns out the function was very much in use. My IDE just didn't know about it because the background indexing process had stalled three days prior without throwing an error. This is the reality of working with AI tools in large codebases. The marketing says they understand your whole repo. The reality is they are only as good as the last time they scanned your disk.
The problem
When you are dealing with 10,000 plus files, the standard context window for any LLM is a joke. You cannot fit a whole repo into a prompt. To solve this, tools like Cursor and Claude Code use different strategies to decide what code to show the model.
Cursor builds a local vector index. It uses a background process to chunk your code and store it so it can perform semantic searches. Claude Code, the new CLI agent from Anthropic, takes a more agentic approach. It uses a combination of file system tools, grep, and recursive searching to find what it needs on the fly.
Our team was seeing massive architectural drift. Junior engineers were using GitHub Copilot to generate snippets that violated our internal design patterns. We had a rule: never use axios in the transport layer. Use our internal fetch wrapper. But because the AI didn't 'see' the wrapper in its immediate context, it kept suggesting axios. We needed a tool that could actually respect the global constraints of a massive project.
What we tried first
We started with Cursor. It's an excellent fork of VS Code. For small to medium projects, it feels like magic. We set up the .cursorrules file to define our architecture. We told it to avoid axios, to use our custom observability hooks, and to follow our specific pattern for feature flags.
For the first week, productivity went up. The @codebase symbol in the chat allowed us to ask questions like 'Where is the auth logic handled?' and get a decent answer. It felt better than ChatGPT because we didn't have to copy and paste code blocks manually. We even used Fireflies.ai to record our architectural reviews and then fed the summaries into Cursor to keep it updated on our decisions.
But as the repo grew, the cracks started to show.
What broke

The primary failure point was index desynchronization. Cursor's background indexing is quiet. Too quiet. In a high-velocity monorepos, where twenty developers are merging PRs constantly, the local index falls behind.
I ran a test. I created a new service, registered it in the main entry point, and then asked Cursor to find it. It couldn't. I had to manually trigger a re-index, which took six minutes. In a flow state, six minutes is an eternity.
More importantly, we hit the 'discovery vs. execution' wall. Finding a bug in a 10,000 file repo is different from fixing it. Cursor is great at the fix once you are looking at the file. It is less reliable at the discovery phase when the bug spans across three different services. It often missed deep references that weren't semantically similar but were functionally linked.
Then there is the cost. While Cursor is a flat $20 monthly fee for the Pro tier, the 'large' index starts to feel sluggish. We noticed it would frequently time out when trying to search the entire codebase for complex architectural patterns. It was fine for local changes, but it lacked the 'bird's eye view' we needed for major refactors.
The fix
We stopped trying to make one tool do everything. We moved to a dual-tool protocol.
We kept Cursor for the visual editing and the surgical, file-level changes. But for codebase-wide discovery and heavy lifting, we brought in Claude Code. Because Claude Code is a CLI tool, it doesn't rely on a pre-built vector index in the same way. It uses a 'search and plan' loop.
If I ask Claude Code to find a bug, it doesn't just look at an index. It runs ls, grep, and cat. It explores the file system like a human developer would.
# The command that saved us
claude "Find all instances of the old billing logic that don't use the new circuit breaker pattern, and list the files."
This agentic discovery is slower for the first 30 seconds, but it is far more accurate. It doesn't suffer from index lag because it is reading the actual files on your disk right now. To manage the architectural drift, we started using Claude Code to run 'linting' tasks on our design patterns. We would tell it to 'Scan the services directory and find any file that imports a library from the prohibited list in our README.'
For a deeper the metrics of this setup, check out our Claude Code vs Cursor for Large Codebases: A Technical Stress Test.
Results
After switching to this dual-tool approach, our incident rate related to 'missing context' dropped by 40%. We stopped shipping those 'oops, I thought this was unused' regressions.
| Feature | Cursor (Pro) | Claude Code (CLI) |
|---|---|---|
| Context Source | Local Vector Index | Live File System + Agentic Search |
| Discovery Speed | Fast (2-5s) | Slower (15-60s) |
| Discovery Accuracy | 70% in large repos | 95% in large repos |
| Cost | $20/mo flat | Usage-based (can be $100+/mo) |
| Refactoring | Best for local files | Best for cross-repo changes |
The unit cost is the major tradeoff. Claude Code uses tokens. For a massive repo, a single complex query can cost $1 to $5 depending on how many files it has to read into context. During a heavy refactor day, I have seen individual developer bills hit $50. For an enterprise project, that adds up. But compared to the cost of a four-hour outage? It is a rounding error.
We found that for discovery, the time to locate a bug in our 1.2M line repo went from 15 minutes of manual searching to about 2 minutes of Claude Code execution. The fix itself took the same amount of time, but the confidence in the fix was significantly higher.
What we would do differently
If I were setting this up from scratch today, I would skip the attempt to use Cursor as a global discovery tool. It isn't built for that. Use it for what it is: a brilliant IDE with high-quality autocomplete and local chat.
I would also be more aggressive about token management with Claude Code. We learned the hard way that you should always use a .claudeignore file. If you let it index your node_modules or dist folders, you are literally burning money.
Lastly, don't trust the 'architectural understanding' of either tool blindly. They both suffer from a lack of long-term memory regarding system constraints. We still require a human senior reviewer for every PR, even if the AI says it followed all the rules. The tools are there to ship faster, not to think for you.
You can find more technical details on Anthropic's Claude Code documentation and Cursor's indexing technical details.