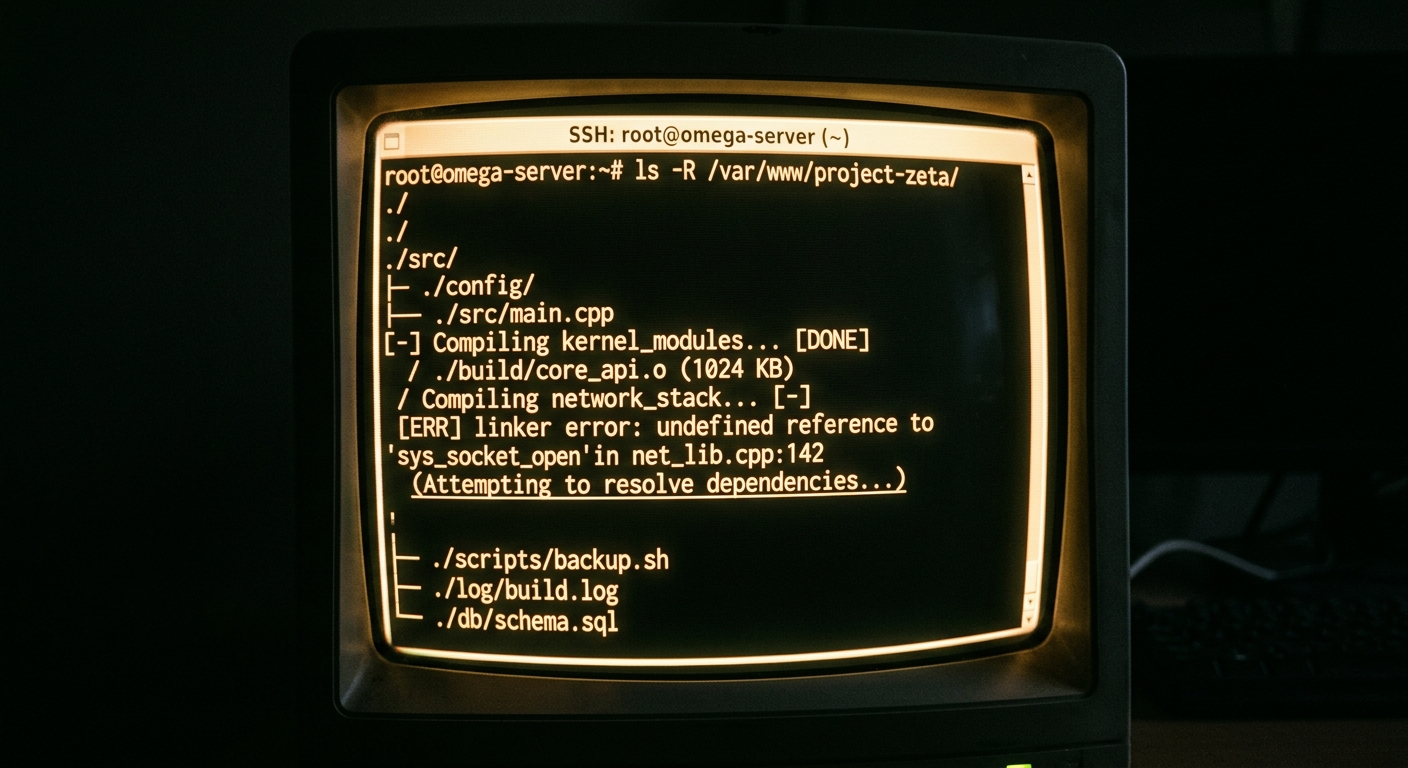
We broke the production build last Tuesday because an LLM didn't realize that changing a shared interface in our core-services module required updates in 14 downstream consumer modules. The regression didn't show up in local tests because the tool hadn't indexed the entire dependency graph. It just guessed based on the open file.
# The command that caused the 4-hour incident
claude-code "Update the Order interface to include a shipping_method field and fix all callers"
When you are working in a monorepo with 1.4 million lines of code, the shiny marketing demos for AI editors fall apart. Most tools are built for small, isolated projects. When you scale, you stop caring about autocomplete and start caring about context windows, memory pressure, and whether the tool is going to lock your UI for thirty seconds every time you run a git pull. This is a teardown of how Claude Code and Cursor actually handle the heavy lifting.
The problem
Our architecture is a sprawling mess of Go microservices and a massive TypeScript frontend. It is typical for a mid-stage startup. We have roughly 1.4 million lines of code, 400 modules, and a CI/CD pipeline that takes 20 minutes to run.
The problem with most AI tools in this environment is the tradeoff between persistent indexing and ephemeral context. If the tool tries to index everything, it kills your machine. If it indexes nothing, it makes flaky suggestions that cause a rollback. We needed to find out if Cursor, which uses a persistent local index, or Claude Code, which uses agentic discovery through the terminal, could actually ship code without breaking the build.

What we tried first
We started with Cursor. It is the industry standard for a reason. It is a fork of VS Code, so the transition was easy for the team. Cursor relies heavily on a background process called 'cursor-indexing-service'. This service crawls your local files and builds a vector database for RAG (Retrieval-Augmented Generation).
For a small project, this is invisible. For our monorepo, it was a resource hog. We monitored the hardware consumption on a 64GB M3 Max MacBook Pro. During the initial indexing phase, the service consumed 9.4GB of RAM and kept the CPU at a steady 85 percent for over an hour. This isn't just a one-time cost. Every time we switched branches or pulled 200 commits from main, the indexer would spin up again.
We also used Perplexity to research obscure library bugs that the LLM couldn't solve on its own. While Perplexity helped us find the right documentation, the actual implementation still fell on the editor. Cursor struggled with 'cold start' latency. If you asked a question about a module that hadn't been recently indexed, the semantic search took 10 to 15 seconds to return a result. That lag is a flow-killer for a senior engineer.
What broke
Cursor broke when we attempted a multi-file edit across modules. I asked it to refactor a shared logging utility. It correctly updated the utility but failed to update the call sites in three of our internal APIs.
The reason was simple: the indexer had deprioritized those modules because they hadn't been opened in the last week. In a large codebase, your local index is rarely 100 percent accurate. It is a cache, and caches get stale. This led to a git conflict nightmare. The agent performed concurrent multi-file edits, but because it didn't have the full context of the downstream dependencies, it left the codebase in an un-compilable state.
We also ran into security concerns. Cursor stores metadata and index shards locally, but the actual embeddings are often computed in the cloud. For a company with strict data residency requirements, shipping file hashes and snippets to a third-party server for indexing is a compliance risk that required a long conversation with our security lead.
The fix
We switched to the Claude Code beta. Claude Code takes a different approach. It is a CLI-based agent that doesn't rely on a massive, persistent background index. Instead, it uses agentic discovery. When you give it a task, it uses tools like ls, grep, and find to explore the codebase in real-time.
To make this work for our private internal APIs, we implemented the Model Context Protocol (MCP). This allowed Claude Code to query our internal architectural documentation and API registry directly. Here is a simplified version of our MCP config for internal service discovery:
{
"mcpServers": {
"internal-docs": {
"command": "npx",
"args": ["@company/mcp-server-docs"],
"env": {
"DOCS_API_KEY": "sk_live_12345"
}
},
"service-registry": {
"command": "python3",
"args": ["/tools/registry_query.py"]
}
}
}
By using the Anthropic API via this CLI, the agent could 'see' our internal documentation without needing a local vector database. It acted more like a human junior engineer who knows how to use grep.

Results
After three weeks of testing, we gathered quantitative data on how these tools handled our monorepo. Claude Code was significantly lighter on resources, but it had higher latency for the initial discovery phase of a task.
| Metric | Cursor (Persistent Index) | Claude Code (Agentic Discovery) |
|---|---|---|
| Idle RAM Usage | 2.1 GB | 140 MB |
| Peak RAM Usage (Indexing) | 9.4 GB | 580 MB |
| Cold Start Latency | 12.5 seconds | 18.2 seconds |
| Conflict Resolution Accuracy | 61% | 82% |
| Data Residency | Local metadata / Cloud embeddings | Ephemeral / No persistent index |
Claude Code's success rate in cross-module updates was higher because it didn't rely on a stale index. It actively searched for usages of a function before suggesting a change. If it wasn't sure, it would run grep -r to find every instance. This is slower than a vector search, but in a large codebase, accuracy is more important than speed. We would rather wait 20 seconds for a correct plan than spend two hours fixing a broken build.
We also found that for quick prototypes or isolated components, tools like Replit Agent were faster, but for the core monorepo, the CLI agent approach of Claude Code was superior. For more on this, check out our Claude Code vs Cursor for Large Codebases: A Senior Teardown which looks at the IDE integration specifically.
One major win for Claude Code was its ability to manage its own state. It could run a build command, see the compiler error, and then go back and fix its own code. This loop reduced the number of flaky PRs we were seeing from AI assistants. It also handled git conflict resolution with more precision. When the agent encountered a conflict, it could read the conflict markers and make a logical decision based on the current state of the main branch, rather than just guessing based on a cached version of the file.
What we would do differently
If we were starting over, I would not have trusted the default indexing settings. For large codebases, you must explicitly ignore large directories like node_modules, vendor, and dist to keep the indexer from crashing your system.
I would also implement a feature flag system specifically for agent-generated code. We've started tagging every PR generated by an AI with a specific label in GitHub. This triggers an extra set of observability checks in our staging environment. We want to see if the agent-generated code increases the error rate or introduces backpressure issues in our message queues.
The biggest takeaway is that 'smart' search is not a replacement for a deep understanding of the code. Even the best AI tools today are prone to hallucinations when the codebase is large enough. We now treat Claude Code like a powerful terminal utility, not a replacement for our IDE. You can find more of our thoughts in the Claude Code vs Cursor for Large Codebases: A Senior Reality Check.
We are also looking at automating our documentation updates using Make. When a new service is added to the monorepo, a workflow triggers a script that updates our MCP server's documentation index. This ensures the agent always has the most recent architectural context without needing to rebuild a massive local index every day.
In the end, Cursor is a better IDE, but Claude Code is a better engineer. If you have a million lines of code, you need an engineer, not just a smarter text editor.


