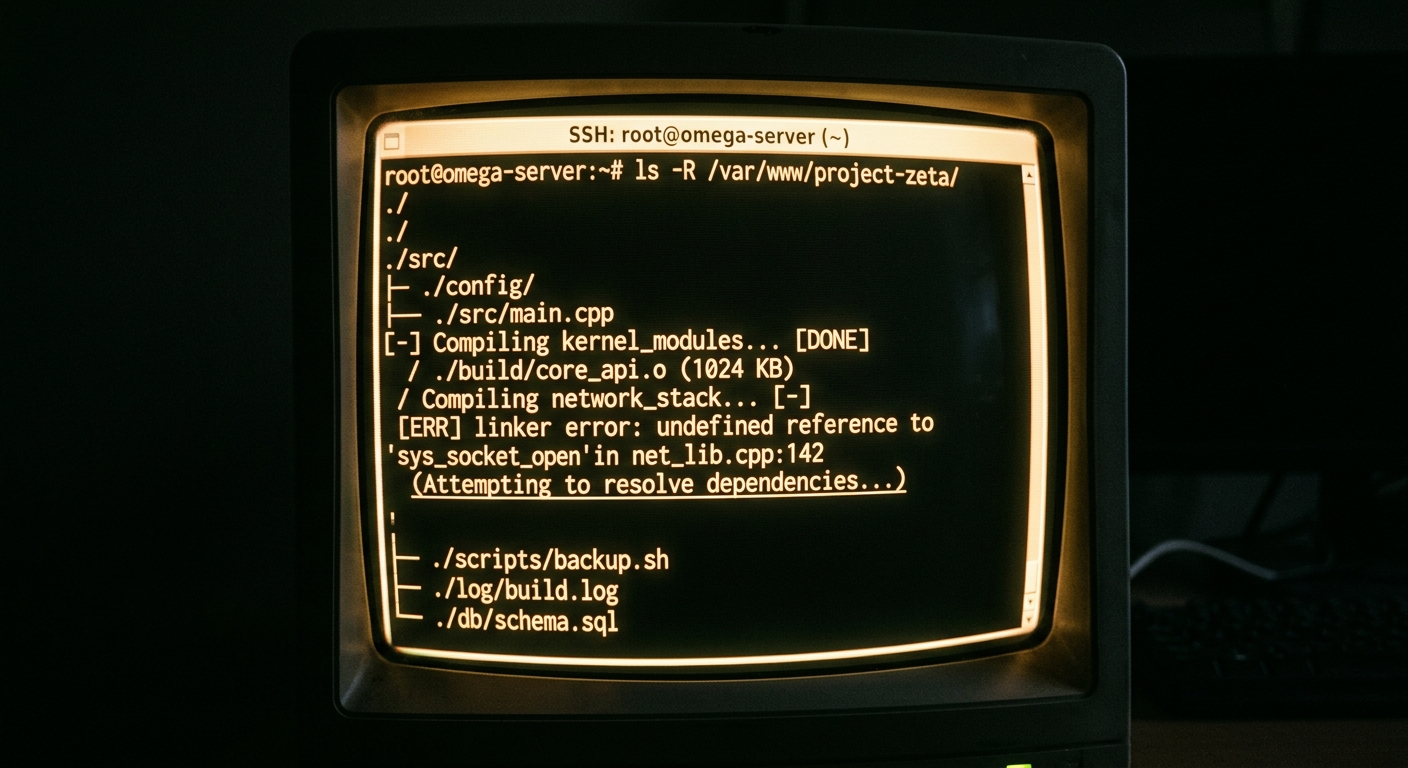
We spent six hours rolling back a deployment last Tuesday because an AI tool missed a reflection based dependency in our legacy event bus. It was a classic regression. We were migrating a core notification service from a monolithic Java repo to a Go microservice. The tool we used for impact analysis swore the path was clear. It was wrong.
# The command that missed the dependency
# cursor --index-repo .
# Result: 0 references found in /legacy/reflection_mapper.java
When you are dealing with a repository exceeding one million lines of code, the shiny UI of an AI editor matters less than its ability to actually see the code. I do not care about auto-complete latency if the tool cannot find the one circular reference that will break the build. This post compares Claude Code and Cursor through the lens of a staff engineer who has to deal with the fallout of flaky migrations.
The problem
Our codebase is a 1.2 million line of code (LOC) monster. It is a mix of legacy Java, modern Go, and a React frontend that has seen better days. We have circular references that have survived three different architecture committees. We have reflection based calls where class names are constructed at runtime from strings stored in a database.
Most AI tools fail here. They work great on a Todo list app or a fresh Next.js project. But when you ask them to map the impact of changing a database schema that is referenced in four different sub-modules across a monorepo, they hallucinate. They miss things because their context window is too small or their indexing strategy is too shallow.
We needed to know if Claude Code, the new CLI tool from Anthropic, could handle the scale better than Cursor, which has been our primary driver for the last year. We focused on three metrics: indexing accuracy, resource consumption on a 32GB RAM machine, and the ability to handle non-linear dependencies.
What we tried first
We started with Cursor. It is the industry standard for a reason. Its integration with VS Code is tight, and its codebase indexing is usually reliable for medium sized projects. For this migration, we enabled the 'Long Context' mode and let it index the entire 1.2M LOC repository.

Indexing a repo of this size is not free. Cursor took about 18 minutes to complete the initial vector embedding. During this time, the local Language Server Protocol (LSP) was sluggish. We watched the process monitor. Cursor's indexing engine peaked at 8.2GB of RAM. If you are running on a base model MacBook, your fans will be at full speed.
We used the @Codebase feature to ask: 'What services will be impacted if we change the payload structure of the OrderValidated event?' Cursor gave us a list of five files. It looked correct on the surface. We proceeded with the refactor based on those suggestions.
What broke
Cursor missed the reflection. In our legacy Java module, we have a DynamicEventHandler that uses Class.forName() to instantiate listeners based on a naming convention. Because there was no direct import statement or static call, the vector retrieval mechanism did not see the connection. The embedding for the event payload and the dynamic loader were not semantically similar enough for the RAG (Retrieval-Augmented Generation) system to flag them.
We shipped the change. The build passed. The tests passed because our test suite did not cover the dynamic loading of that specific edge case. Production hit a runtime exception within ten minutes. We had to trigger a rollback and start a post-mortem.
This is the inherent weakness of vector based retrieval in large codebases. It relies on proximity in high dimensional space. If your code is connected by clever logic rather than explicit syntax, the index is blind. We needed something that could actually 'read' the filesystem like an engineer would, rather than just searching a database of embeddings. This is where we turned to Perplexity to research alternative agentic approaches before settling on a trial of Claude Code.
The fix
We switched to Claude Code. Unlike Cursor, which lives inside the IDE and relies heavily on its pre-computed index, Claude Code is a CLI agent. It uses a tool-calling loop. When you ask it a question, it does not just look at an index. It can run ls, it can grep, and it can read specific files on demand.
claude "Find all references to OrderValidated, including dynamic or reflection-based lookups in the legacy folder."
Claude Code's approach is agentic file system traversal. It started by searching for the string 'OrderValidated'. When it found the event definition, it did not stop. It looked at the folder structure. It saw the DynamicEventHandler and, crucially, it read the logic that constructed class names. It then proactively searched for classes that followed that naming pattern.
It found the hidden dependency in three minutes. It did not need a 20-minute indexing phase because it explored the codebase dynamically. It was slower to answer than Cursor, but it was accurate.
| Feature | Cursor (RAG/Vector) | Claude Code (Agentic) |
|---|---|---|
| Initial Indexing Time | 18 minutes | 0 minutes |
| Local RAM Usage | 8GB+ | < 1GB (CLI based) |
| Accuracy (Reflection) | Low | High |
| Accuracy (Static) | High | High |
| Token Cost | Included in subscription | Usage-based (High) |
| Multi-repo Support | Limited | Native (can path out) |
Claude Code also handled our multi-repo orchestration better. We had a dependency split across a separate microservice repo. With Cursor, you have to open both folders in a workspace and hope the indexer stays sane. With Claude Code, you can just point the agent to the parent directory. It treats the entire file system as its playground. For more on this, see our detailed Claude Code vs Cursor for Large Codebases: A Senior Teardown analysis.
Results
After migrating the notification service using Claude Code's impact analysis, we saw zero regressions in the subsequent three releases. The tool found circular references in our build scripts that we did not even know existed.
However, the cost is a major tradeoff. Cursor is a flat $20 per month. Claude Code uses the Anthropic API directly. For a heavy day of architectural migration on a million line repo, we spent $45 in tokens. The agent reads a lot of files to build its own context. It is effectively doing the work of a senior dev, but it charges by the word.
We also had to look at security. Cursor offers a 'Privacy Mode' where code is not used for training, but the index still lives on their servers unless you use a local model. Claude Code, being a CLI tool, gives you more control over what is sent, but the telemetry is still a factor for enterprise compliance. We ended up using Zapier to automate a script that scrubs sensitive environment variables from our local logs before they could ever be caught in a terminal copy-paste, though Claude Code itself is fairly disciplined about ignoring .env files.
For a deeper the specific performance metrics we tracked, check out our other report on Claude Code vs Cursor for Large Codebases: A Senior Teardown.
What we would do differently
If we had to start this migration over, we would not pick one tool. We would use Cursor for the tactical work. It is still the best for writing a new function, refactoring a single component, or generating boilerplate. The UX of seeing the code change in real time is superior for local development.
But for the strategic work, we would start with Claude Code. We would use it to generate the initial impact report and the migration plan. The agentic traversal is simply more reliable for finding the 'unknown unknowns' in a large, messy codebase.
We would also implement a stricter feature flag policy earlier in the process. AI tools, no matter how advanced, are still prone to missing edge cases in legacy systems where the original authors are long gone. You cannot rely on a tool to understand 'why' a weird hack exists. You can only rely on it to find where that hack is hidden.
We also learned that token management is the new resource management. Just as we used to optimize for memory leaks, we now have to optimize our prompts to prevent Claude from reading the entire node_modules folder. For teams on a budget, Cursor's indexed approach is much more sustainable for daily use. Claude Code is the heavy artillery you bring out when the problem is too complex for a standard search.
In the end, the choice between Claude Code and Cursor for large codebases is a tradeoff between cost and certainty. Cursor is the reliable daily driver. Claude Code is the specialist you hire to find the bug that is going to cost you your weekend.