
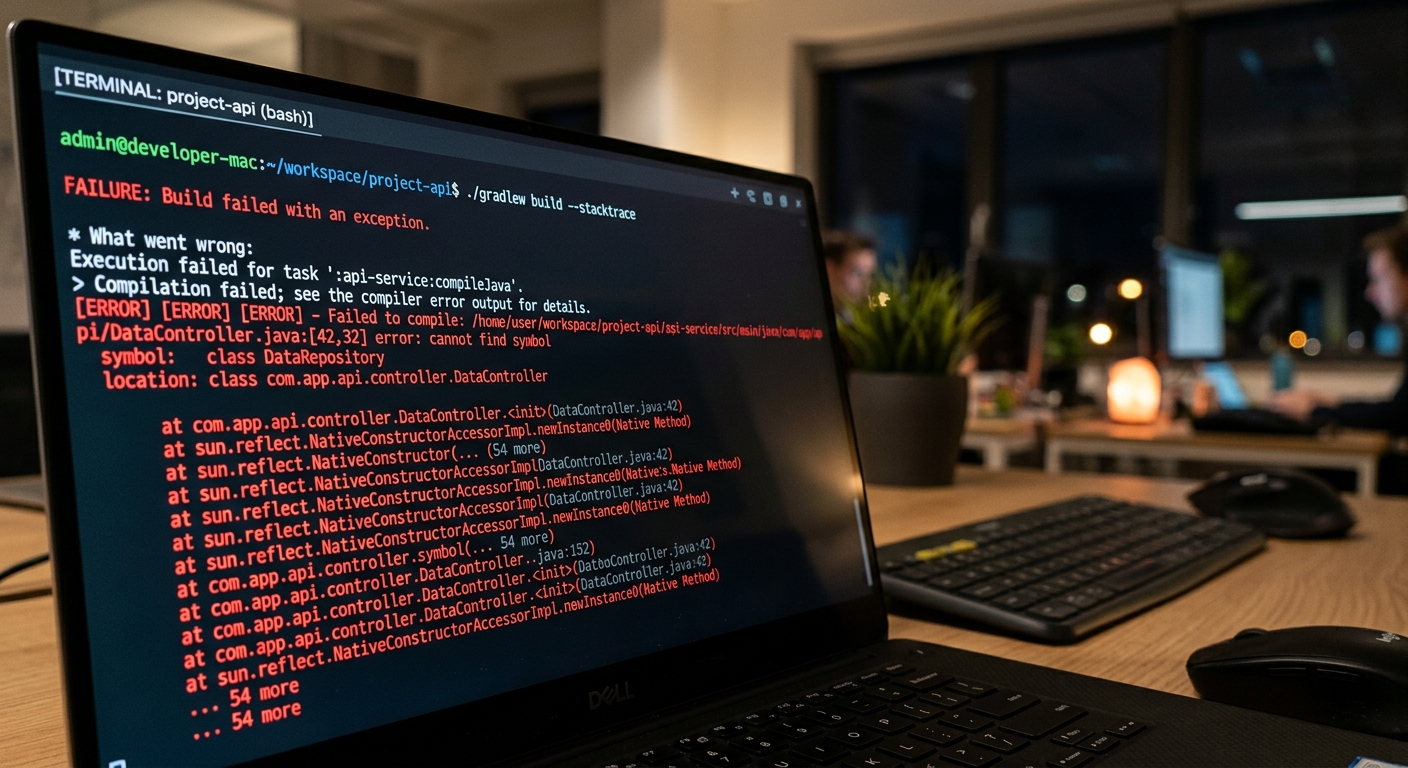
I spent four hours yesterday debugging a circular dependency that an AI tool introduced because it did not look at the full dependency graph. It was a classic case of an agent being too confident with too little context. In a 200,000 line codebase, these tools are not just helpers. They are high-risk contributors that can cause a massive rollback if you do not watch them.
# The command that broke the build
claude "refactor the auth middleware to use the new session store"
The refactor looked correct in isolation. The tests passed in the modified file. But the agent did not realize that a secondary service relied on the specific export structure I had just nuked. This is the reality of using Claude Code or Cursor in a large codebase. They are powerful, but they are often blind to the side effects that a senior human dev would catch in a second.
Why this list
Most reviews of AI coding tools are written by people building Todo apps or landing pages. They do not deal with 500-table databases, legacy monoliths, or complex microservices. When you are operating at scale, the criteria for a tool changes. You do not care about how fast it can write a boilerplate React component. You care about context retrieval, the reliability of the agentic loop, and whether the tool creates more work in the form of regressions and flaky tests.
I have been testing Claude Code, the new CLI tool from Anthropic, against Cursor, the established IDE, for the past three months. This list is based on shipping actual production code and dealing with the inevitable incidents that follow.
1. Context retrieval: Indexing vs. Grepping
Cursor relies heavily on local indexing. It builds a vector store of your codebase to provide context for its queries. This is great for finding where a function is defined, but it often misses the logical connections between disparate parts of a large system. If your codebase is too large, the index can become stale or incomplete.
Claude Code takes a different approach. It uses an agentic loop to explore the codebase. It runs commands like ls, grep, and cat to find what it needs. This is slower, but in my experience, it is more accurate for deep architectural changes. It does not just rely on what is in a vector database. It looks at the files as they exist on disk right now.
| Feature | Cursor | Claude Code |
|---|---|---|
| Context Method | Vector Index / Embeddings | Agentic Search / Tool Use |
| Speed | Very Fast | Moderate (Agentic loops take time) |
| Accuracy in Large Repos | Variable | High |
| Disk Usage | High (Indexing) | Low |
If you are working in a repo where the structure is constantly shifting, Cursor's index can feel like a bottleneck. Claude Code feels more like a senior dev who just joined the team and is grepping through the source to understand the flow. For a deeper look at this dynamic, see our Claude Code vs Cursor for Large Codebases: A Senior Reality Check.
2. The terminal as the primary interface
Claude Code lives in your terminal. This is its greatest strength and its greatest weakness. For a staff engineer, the terminal is home. Being able to run claude "run the migrations and update the schema file" without leaving the CLI is a massive productivity boost. It fits into existing workflows involving git and build tools.
Cursor is a fork of VS Code. It provides a visual interface for everything. This is better for reviewing diffs. Reading a 500-line diff in a terminal is a nightmare. Cursor's "Composer" mode allows you to see multiple file changes side-by-side with clear red and green highlights. This makes it much easier to catch a regression before you commit it.
However, Claude Code has a feature that Cursor currently lacks: the ability to execute shell commands as part of its reasoning loop. If you ask Claude Code to fix a bug, it can run the tests, see the failure, and then try a different fix. It creates its own feedback loop. Cursor requires you to manually run the tests and feed the output back into the chat. This manual step is where many errors creep in.

3. Agentic loop and test execution
Claude Code is an agent. It does not just suggest code. It attempts to complete a task. This includes running build scripts and linters. In a recent project, I used it to upgrade a set of deprecated API calls. It ran the build, caught the type errors from the TypeScript compiler, and fixed them iteratively.
This sounds like magic, but it creates a backpressure problem. If the agent is too aggressive, it can burn through your token quota and your patience. I have seen Claude Code get stuck in a loop where it fixes one bug, introduces another, and then tries to fix that one. This is where PostHog or similar observability tools become useful. You need to monitor the actual impact of these changes on your product metrics. Are the features shipped by AI resulting in more bugs or lower conversion? You cannot just trust the tool.
Windsurf is another player in this space that offers similar agentic flows. Like Claude Code, Windsurf tries to understand the intent of the developer, but it does so within an IDE environment. It is a middle ground between the CLI-heavy Claude Code and the UI-heavy Cursor.
4. Cost and token management in large repos
Large codebases are token hungry. When you provide context to an LLM, you are paying for every line of code sent in the prompt. Cursor has a subscription model that includes a certain number of "fast" requests. Claude Code uses your Anthropic API key directly.
In a large repo, a single request to Claude Code can cost $0.50 to $2.00 depending on how much context it pulls in. If you are not careful, you can spend $50 in a single afternoon. This is a significant tradeoff. You are paying for the agent's ability to "think" and search.
Cursor is generally more predictable in its pricing for individual developers. But for an enterprise, the API-based model of Claude Code might be more transparent. You can see exactly which projects are consuming the most tokens. If you find yourself hitting rate limits with standard models, using a provider like Groq for faster inference or Gemini for larger context windows might be necessary, though Claude Code is currently locked to the Anthropic ecosystem.
5. Integration with the stack
When you are shipping at scale, you are not just writing code. You are managing deployments, feature flags, and observability.
Cursor integrates well with the VS Code ecosystem. Any extension you use for ChatGPT or Docker will work there. It feels like a part of your existing setup.
Claude Code feels more like a standalone collaborator. It is excellent at tasks that involve the filesystem and the shell. For example, if you need to find all instances of a specific flag in your code and generate a report, Claude Code is faster. It can pipe output to files or other CLI tools.
But it lacks the deep integration with things like a debugger. If I am trying to step through a complex race condition, I am going to use Cursor. The visual debugger is something a CLI agent cannot replace. If you are interested in how these tools affect the bottom line, our case study on AI for Client Onboarding shows the unit economics of using AI in production environments.
What to try first
If you are a terminal-first developer who spends most of their time in Vim or Tmux, try Claude Code first. Its ability to run bash commands and its agentic search make it a powerhouse for refactoring and exploratory work. You can find the installation guide in the Claude Code Documentation.
If you prefer a visual workflow and want the best diffing experience currently available, go with Cursor. Its indexing is usually enough for daily feature work, and the Composer UI is the gold standard for AI-assisted editing.
Do not expect either tool to understand your entire architecture perfectly. Always run your full test suite before you ship. AI tools are great at solving local problems, but they are still quite bad at understanding the global state of a complex system. They are a force multiplier, but they can also multiply your technical debt if you do not treat every suggestion as a potential incident waiting to happen.


